
纸上得来终觉浅,觉知此事要躬行。 每次读书或者阅读文章都感觉“哦哦,原来是这样”,以为自己懂了,其实只是把别人的东西记到脑子里,遗忘的很快。好记性不如烂笔头,写写总归没有坏处。
好,正式开始,先上源码,比较长就直接给链接了。openjdk11的HashMap源码链接
当然,这里只会挑比较重要的部分进行记录,比如hash(),put(),get()等常用函数。
hash()函数
首先看一下hash()函数:
1 | |
看到这个公式有点蒙,先看»>是个什么意思。这个符号与»的差别就是:
»>是不分正负的,右移统统在高位补零。在研究这个问题时发现,int型在进行移位运算时(»/»>/«)范围在0~31之间,超出后按零处理。(知识补充)
这里是将传入的对象的hash值的高16位与低16进行运算,为什么要这样呢? 因为这里还有一步没在hash函数里显示所以不太能看懂,我们来看下面这段代码。
1 | |
这虽然不在hash函数里,但是也起着重要的作用,这段计算公式可能不太好理解,换成下面这样可能就好理解多了:
1 | |
之所以,高16为与低16位进行异或,是因为防止高位的变化对整个hash函数没有影响,这就好比10的倍数对10取余,无论倍数怎么改变,最终取余都为0,而高16为与低16位进行异或以后,高位的变化就会反映出来,有效的避免了这种情况,从而减少了hash冲突,HashMap的hash函数设计的还是比较巧妙的。
其实,对于(n - 1) & hash 还有另一种解释,只不过这种解释比较难理解。
n为2的整数次幂,也就是像4,8,16,32…这样的数,这样的数有一种规律,就是减一以后二进制低位变成全一。 假设我们的数组长度为5(0101),现在有待插入的数据1,2,3,4,5,6。(hash & (n - 1))
0001(1) & 0100(4) = 0
0010(2) & 0100(4) = 0
0011(3) & 0100(4) = 0
0100(4) & 0100(4) = 4
0101(5) & 0100(4) = 4
0110(6) & 0100(4) = 4
可以看出,不管其他位置怎么变化与操作的结果只和4的二进制1的位置有关,这样的话,hash冲突就比较严重了,并且十分浪费空间。
当数组长度为2的整数次幂时:
假设长度为4(0100),待插入数据1,2,3,4,5,6。
0001(1) & 0011(3) = 1
0010(2) & 0011(3) = 2
0011(3) & 0011(3) = 3
0100(4) & 0011(3) = 0
0101(5) & 0011(3) = 1
0110(6) & 0011(3) = 2
这时就能很好的减少hash冲突,其实这里还是和取余的意思相同,位操作相比于%速度更快一些。
但是这两段代码想要转换,必须满足一个条件:n是$2^k$,这也是为什么我们在声明map的大小时需要是2的整数次幂了。
1 | |
这段代码保证了即使我们传入的值不是2的指数倍,它也会自动给我们转换化成最接近且不小于我们指定大小的2的指数倍。(对与HashMap将数组大小定义为2的整数次幂,其实还有一个作用,在resize()中介绍)
综上所述,hash函数应该为:
1 | |
put函数
在看put源码之前,我们先来看一下我们的值在map中是如何存储的。
看下面这张图(注:这里并不是map实际的插入过程,只是简单的将插入的数据对4取余得到的结果):
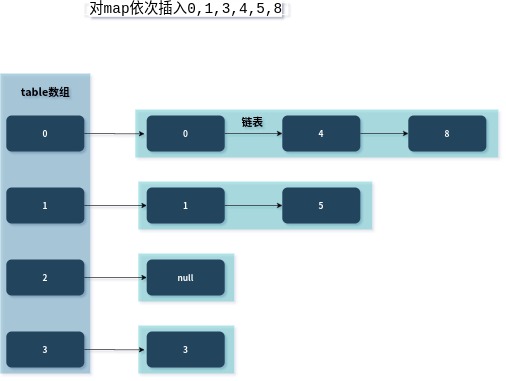
虽然看起来效果还不错,但是这里却有个问题。
即使hash函数能够大大降低冲突,但是也不能完全避免,当出现下面这种情况时,map的查找速度就会大大降低:
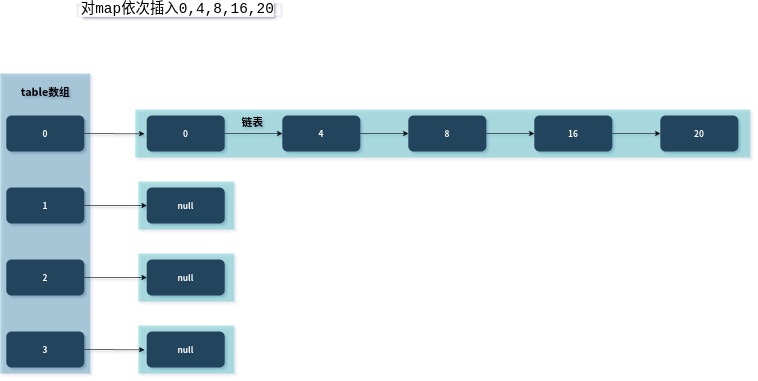
可以看到所有元素都集中到一条链表上了,这样的话,我们查询元素的时候,就需要遍历链表了,它的时间复杂度就会从O(1)下降到O(n),即使这个概率很小。当然,java已经为我们解决了这个问题,来看看他是怎么解决的。
1 | |
对于put()函数在总结一点,这里当表内的一个bucket(有的叫桶,先理解表中一个链表)长度大于等于7(也就是第八个)时会进行树化,防止查询效率较低,这里树采用的是红黑树(一种比较稳定的数据结构查询、插入以及删除时间复杂度都是log(n))。当删除到小于7的时候会再次转化为链表结构,因为维持红黑树是比较耗时的,数据量小就没必要使用红黑树了。使用红黑树的效果大致如下:
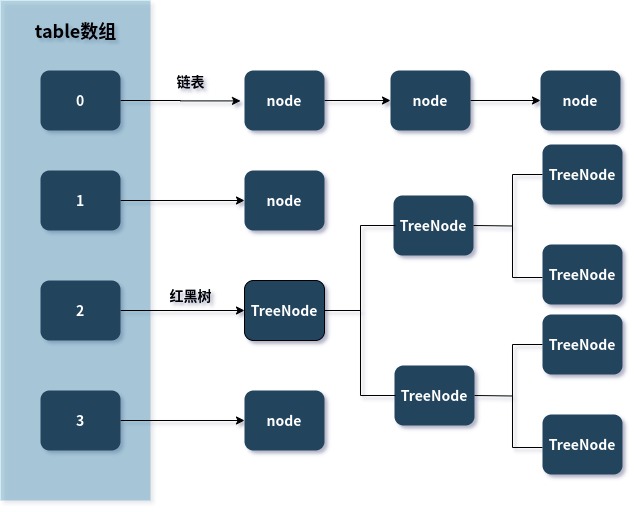
get()函数
1 | |
get函数比较简单,没有太多要总结的。
resize()函数
这个函数主要有两个功能。
- 1.初始化table数组
- 2.对table数组进行扩容
下面直接看源码:
1 | |
这里再讲一下,2的整数次幂对扩容的作用
因为这里对数组扩容也是两倍两倍的增加,最终数组的长度也是一个2的整数次幂。
比如说原本数组长度为4,扩容以后为8,那这里就涉及到重新计算hash值了,以2,3,4,5,6,7为例。
0010(2) & 0011(3) = 0010(2) 0010(2) & 0111(7) = 0010(2)
0011(3) & 0011(3) = 0011(3) 0001(3) & 0111(7) = 0011(3)
0100(4) & 0011(3) = 0000(0) 0100(4) & 0111(7) = 0100(4)
0101(5) & 0011(3) = 0001(1) 0101(5) & 0111(7) = 0101(5)
0110(6) & 0011(3) = 010(2) 0110(6) & 0111(7) = 0110(6)
0111(6) & 0011(3) = 0011(3) 0111(7) & 0111(7) = 0111(7)
可以看出规律,小于为扩容前数组的大小的是不会发生变化的,而大于原先数组的都在扩容后数组长度减一后二进制最高位上加了个一。这样的话是否移动以及移动到哪就可以通过新hash值与原数组长度按位与,如果是0就不动,如果是1就移动到原索引加上扩容前数组长度。以3,5为例:
根据上面结果可知,3(0011) & 4(0100) = 0 不动,5(0101) & 4(0100) = 1(移动到1(原索引位置)+4 = 5)
具体代码如下:
1 | |
总体来说,put,get,resize这三个方法深层次去挖掘的话,还是比较难的,其中也涉及到比较难的数据结构(红黑树),这对理解HashMap的源码产生了一些影响。但是抛去细节来说,只要慢慢阅读,还是能够清楚的代码的答题思路的。